728x90
해시(Hash)
- 임의의 크기를 가진 데이터를 고정된 크기의 데이터로 매핑하는 함수
문제 1) 프로그래머스: 완주하지 못한 선수
* 라이브러리 없이 풀이
def solution(participant, completion):
part = {}
for person in participant:
part[person] = part.get(person, 0) + 1
for person in completion:
part[person] -= 1
result = [key for key, value in part.items() if value > 0]
return result[0]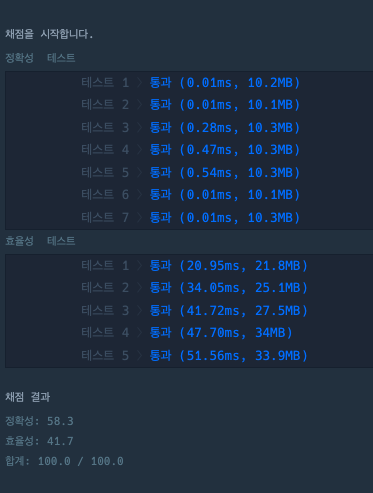
이 코드의 시간 복잡도는 O(n)
for 문을 사용하여 participant 리스트의 모든 요소를 반복하고, part 딕셔너리에 각 요소가 몇 번 등장했는지를 저장
이 과정에서 n번의 연산이 수행
그리고 다시 for 문을 사용하여 completion 리스트의 모든 요소를 반복하고, part 딕셔너리에서 해당 요소의 값을 1 감소
이 과정에서도 n번의 연산이 수행
마지막으로, 딕셔너리의 items() 메서드를 사용하여, 값이 0보다 큰 key를 리스트에 저장
이 과정에서도 n번의 연산이 수행
* 라이브러리 사용해서 풀이
import collections
def solution(participant, completion):
answer = collections.Counter(participant) - collections.Counter(completion)
return list(answer.keys())[0]
이 코드의 시간 복잡도는 O(n)
collections 모듈의 Counter 클래스를 사용하여 participant 리스트와 completion 리스트의 각 요소의 개수를 카운트
이 과정에서 n번의 연산이 수행
그리고, Counter 객체 간 빼기 연산을 수행하여 participant 리스트에만 있는 요소를 찾기
이 과정에서도 n번의 연산이 수행
마지막으로, 결과를 리스트로 변환하여 반환
이 과정에서는 O(1)의 시간 복잡도가 소요
탐욕법(Greedy)
- 최적해를 구하기 위해 사용되는 알고리즘 디자인 기법 중 하나
- 이 방법은 각 단계에서 최선의 선택을 하는 것으로 전체적인 최적해를 구하는 방법
문제 2) 프로그래머스: 체육복
* 풀이 1
def solution(n, lost, reserve):
u = [1] * (n+2)
for i in reserve:
u[i] += 1
for i in lost:
u[i] -= 1
for i in range(1, n + 1):
if u[i - 1] == 0 and u[i] == 2:
u[i - 1:i + 1] = [1, 1]
elif u[i] == 2 and u[i + 1] == 0:
u[i: i+2] = [1, 1]
return len([x for x in u[1:-1] if x > 0])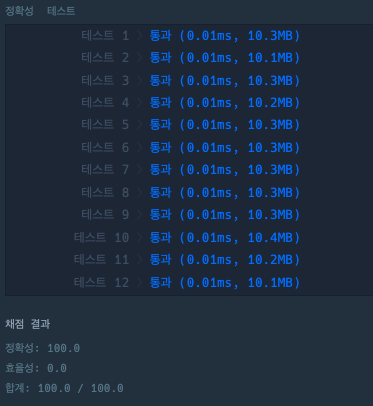
위 코드의 시간 복잡도는 O(n)
u의 크기는 n+2이며, 여기에 여벌 체육복을 가진 학생들의 체육복 개수를 더해주고,
도난당한 학생들의 체육복 개수를 빼주는 과정에서 O(reserve + lost)의 시간이 걸린다.
u 리스트를 순회하면서 체육복을 빌려줄 수 있는 경우에 대해서만 처리해 주기 때문에, 이 부분에서는 O(n)의 시간이 걸린다.
따라서 전체 시간 복잡도는 O(reserve + lost + n) = O(n)
* 풀이 2
def solution(n, lost, reserve):
common = set(reserve) & set(lost)
reserve = set(reserve) - common
lost = set(lost) - common
for x in sorted(reserve):
if x - 1 in lost:
lost.remove(x - 1)
elif x + 1 in lost:
lost.remove(x + 1)
return n - len(lost)
주어진 코드의 시간 복잡도는 O(nlogn)
set 자료형을 사용하여 중복되는 원소를 제거
이 연산의 시간 복잡도는 O(n)
그 이후에 sorted 함수를 사용하여 reserve 리스트를 정렬
이 연산의 시간 복잡도는 O(nlogn)
그리고 for 루프를 사용하여 reserve 리스트의 각 원소를 하나씩 탐색
이 연산의 시간 복잡도는 O(n)
문제 3) 프로그래머스: 큰 수 만들기
def solution(number, k):
collected = []
for i, num in enumerate(number):
while len(collected) > 0 and collected[-1] < num and k > 0:
collected.pop()
k -= 1
if k == 0:
collected += list(number[i:])
break
collected.append(num)
if k > 0:
collected = collected[:-k]
else:
collected
return ''.join(collected)for문은 number의 길이만큼 반복하므로, 시간 복잡도는 O(len(number)) = O(n)
while문은 최악의 경우 각 숫자마다 k번 실행될 수 있다. 따라서 시간 복잡도는 O(k)
join문 리스트의 모든 문자열을 결합하므로, 시간 복잡도는 O(n)
위에서 언급한 세 단계의 시간 복잡도를 종합하면, 전체 시간 복잡도는 O(n) * O(k) + O(n)
여기서 for loop와 while loop는 중첩되어 있으므로, 두 루프의 시간 복잡도를 곱해야 한다.
최종적으로 전체 시간 복잡도는 O(n * k + n)이 된다.
정렬(Sort)
- 데이터를 원하는 순서대로 재배열하는 알고리즘
1) 알고리즘 종류
- 버블 정렬(Bubble Sort)
- 선택 정렬(Selection Sort)
- 삽입 정렬(Insertion Sort)
- 퀵 정렬(Quick Sort)
- 병합 정렬(Merge Sort)
- 힙 정렬(Heap Sort)
- 계수 정렬(Counting Sort)
- 기수 정렬(Radix Sort)
문제 4) 프로그래머스: 가장 큰 수
def solution(numbers):
# numbers 리스트를 문자열 리스트로 변환
numbers = [str(x) for x in numbers]
# 문자열 리스트를 정렬합니다. 이때, sort 함수를 사용하며, 정렬 기준을 설정한다.
# 각 숫자를 4번 반복하여 4자리 문자열로 만듭니다. 예를 들어, 6을 6666으로 만든다.
# 4자리 문자열의 첫 4글자를 추출하여 정렬 기준으로 사용
# 정렬 기준은 내림차순으로 설정
numbers.sort(key=lambda x: (x * 4)[:4], reverse=True)
# 모든 요소 값이 0이라면?
# 만약 정렬된 리스트 numbers의 첫 번째 원소가 '0'이라면,
# 결과값으로 '0'을 반환
# 이때, 첫 번째 원소가 '0'인지를 확인하는 것으로 체크
if numbers[0] == '0':
answer = '0'
else:
answer = ''.join(numbers)
return answer시간 복잡도는 sort 함수의 시간 복잡도에 의해 결정된다.
sort 함수의 시간 복잡도는 일반적으로 O(nlogn)
이 코드의 전체 시간 복잡도도 O(nlogn)
어려웠던 점
- 정렬에서 일정한 규칙 찾기
- 탐욕법 체육복 문제 풀이 1번에서 슬라이스로 데이터 값 변경
728x90
SMALL
'Develop > 기초지식' 카테고리의 다른 글
| 자료구조 & 알고리즘(문제 풀이 포함) - 5 (0) | 2024.07.30 |
|---|---|
| OrderedDict 사용해보기 (0) | 2023.04.26 |
| 좋은 코드 란? (0) | 2023.04.20 |
| 자료구조 & 알고리즘 - 3 (0) | 2023.04.12 |
| 자료구조 & 알고리즘 - 2 (0) | 2023.04.11 |
